
Matching Showcase
Matching within a single list or database
Want to check for duplicates within a single list or dataset?
Duplicated entries within a single list or dataset can be identified quickly and easily. Simply enter the details of the person and their address and let Kleber find your duplicates using fuzzy logic and phonetics.
Overview
Duplicates within a single list or dataset can cause your data to become unwieldy and make mail outs or promotional give aways etc expensive.
Duplicates in your dataset could be:
- the same person entered multiple times at the same address with slight spelling mistakes in either the name OR address
- the same person entered multiple times at different addresses
- the same person entered multiple times at different businesses
- multiple people entered for the same address (which is important if you only want to send one item to the household), etc.
Finding these duplicates can be difficult especially if they are spelt differently.
This is where Kleber can help! It uses fuzzy logic, phonetics and intelligent weighting to ensure if identifies as many duplicates as possible.
 EXPERT TIP
EXPERT TIP

Run these match methods each time you create or change a record in your database and store the match keys with them.
This allows for quick and easy match queries to be run at any time in your database – either as part of the record creation/change or as a batch report etc.
How was this demo created?
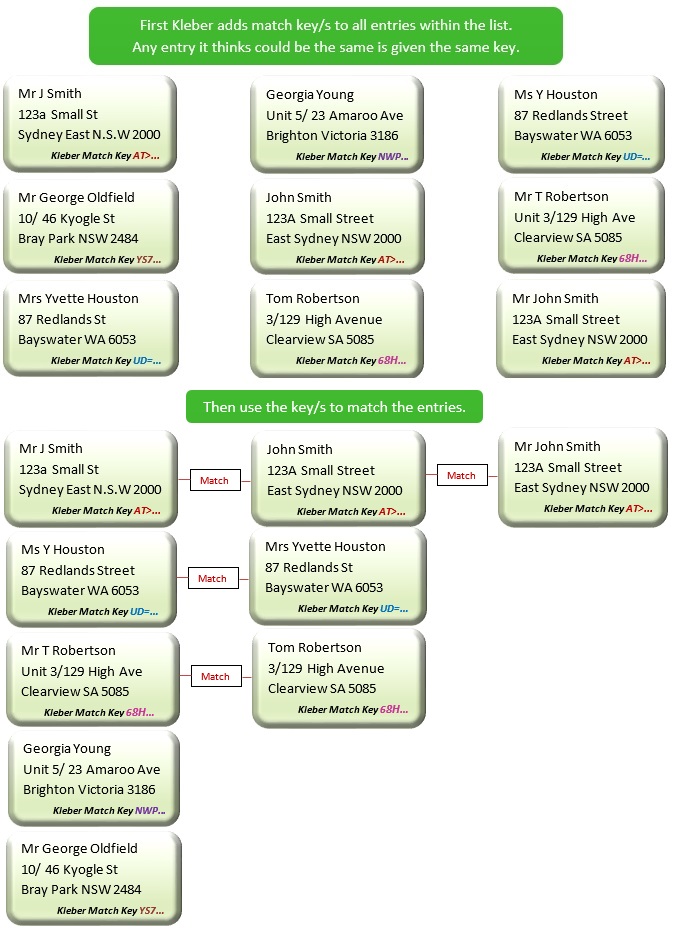
This image above shows a simplified example of what is really occurring when you use a Kleber Match method.
The method chosen for this example is DataTools.Match.PersonNameAndAddress.Au.CreateKeys, but the process is the same for all match methods.
First – enter the details required (in this case the person’s name and address) and run the method. Kleber will generate unique match keys to identify the different elements of the business name and address.
The Kleber CreateKey methods generate identical keys by firstly identifying the elements of the supplied data using advanced parsing; then applying the process to each of the elements depending on their meaning and lastly placing the processed elements together to create the final match key.
Creating match keys this way means that even if the data is provided in different fields; in a different order; formatted differently or misspelt – identical keys are created. With identical keys finding matches is as easy as finding where the keys match exactly. This means no “like” matching is required because all the “fuzziness” has been taken into account when the key is generated.
Specific example of match keys
If we look specifically at the two entries below you can see the actual input given and output provided using Kleber.
The DataTools.Match.PersonNameAndAddress.Au.CreateKeys used in this example creates nine different keys depending on how closely or loosely matched you need the person’s name and/or address to be.
You could use all or any of the keys provided to find a match.
The keys could have been generated when you created the record; changed a record; or as part of a batch exercise to find all matches. We suggest that once you create the keys – that you save them in your database with your data to speed up any future matching requirements.

What are the differences between Tight, Standard and Loose Keys?
Match keys are created in 3 varieties, Tight, Standard and Loose.
Tight keys allow for little difference between matches. Tight keys are useful for matching where no user interaction is available.
Loose keys will identify a lot more matches some of which may be questionable but will assist in identifying the last couple percent of matches that are difficult to find. Loose Keys should never be use without user interaction to verify matches.
Standard keys are a good balance between Tight and Loose key and depending on the outcome required may be used without user interaction.
It’s best to test keys on large quantities of data verifying the results to see which key or what combination of keys best suit your business requirements.
Click here for a more detailed explanation of the match keys.
License considerations.
The match methods are proprietary to DataTools. Users should read the DataTools terms and conditions to make sure intended use complies. They can be found here.
Developer Guides Integration Partners
About Kleber
Your data can be your greatest asset. But when it isn’t right – it impacts so many areas of your business.
At Kleber – we make data accurate.
Kleber provides simple and convenient real time access to transaction and batch processing services in a single web services API platform. Simplify your systems and access more data without the hassle of dealing with multiple vendors.

Start using Kleber today!